
When your core banking system processes 40 million transactions a day, you don’t discover problems from customer complaints. When your e-commerce platform handles festival season traffic spikes, you can’t afford to troubleshoot in the dark. When regulators ask for audit trails spanning three years, you need answers in hours, not weeks.
This is the reality of running enterprise systems at scale. And yet, logging, monitoring, and observability remain among the most underestimated aspects of enterprise IT programs until something breaks—usually at the worst possible time.
Most C-level conversations about digital transformation focus on features, timelines, and budgets. Fair enough. But the infrastructure that tells you whether your systems are actually working, where they’re failing, and why—that conversation happens too late, if at all. By the time teams realize they can’t diagnose production issues quickly, or comply with audit requirements, or understand why performance degrades under load, they’re already in trouble.
This isn’t a technology problem. It’s an execution and governance problem. And it’s one that separates enterprises that deliver reliably from those that stumble through every release cycle.
Why This Matters More Than Most Executives Realize
Here’s what actually happens in large enterprises.
You launch a new digital channel. It works well in testing. It goes live. Three months later, response times start degrading during peak hours. Your operations team can’t pinpoint the bottleneck. Is it the application layer? Database queries? Third-party API calls? Network latency? Without proper observability, every diagnosis is guesswork. Every fix is a gamble.
Or consider compliance. Your auditors need proof that specific user actions were logged, that sensitive data access was tracked, and that configuration changes were recorded. If your logging infrastructure wasn’t designed with this in mind from day one, you’re now asking developers to retrofit audit trails into production systems. This means code changes, testing cycles, and deployment risk, all because observability was treated as an operational afterthought rather than a foundational requirement.
Then there’s scale. A system that logs adequately for 100,000 users will drown your infrastructure when it reaches 10 million. Log volumes explode. Storage costs spiral. Search performance collapses. What started as a simple operational tool becomes a performance liability and a budget problem.
These scenarios play out across industries, such as banking, insurance, retail, manufacturing, and healthcare. The patterns are consistent. The root cause is almost always the same: observability wasn’t treated as a first-class concern during system design and delivery.
What Goes Wrong in Enterprise Programs
Most enterprise IT initiatives follow a familiar trajectory. Requirements are gathered. Architectures are designed. Development begins. Testing happens. And somewhere in that process, logging and monitoring get defined as “non-functional requirements,” a polite way of saying they’ll be handled later.
Later arrives during user acceptance testing, or worse, after go-live. That’s when someone asks: “How do we know if the system is performing well?” or “Can we track what happened when that transaction failed?” or “Why can’t we see end-to-end latency across our microservices?”
Now you’re playing catch-up. And catch-up in enterprise programs is expensive.
Development teams add logging statements reactively, which means inconsistent log formats across services. Operations teams cobble together monitoring dashboards that don’t align with business KPIs. Security teams discover that audit logs don’t capture the granularity they need. Performance teams realize that distributed tracing wasn’t implemented, so diagnosing issues across 15 microservices is nearly impossible.
Each gap triggers rework. Each rework delays timelines. Each delay erodes stakeholder confidence.
The deeper problem isn’t technical, it’s organizational. Logging and observability span multiple domains: development, operations, security, compliance, and infrastructure. In most enterprises, these groups work in silos. Nobody owns the end-to-end observability strategy. So it doesn’t get built coherently.
The Governance Gap
Enterprise programs struggle with observability because it requires cross-functional decision-making early in the program lifecycle.
What should be logged? How long should logs be retained? What metrics matter for business operations versus technical operations? How do you ensure sensitive data isn’t leaked in log files? Who gets access to production logs? How do you handle log data across multiple geographies with different privacy regulations?
These aren’t questions that get answered in sprint planning meetings. They require input from legal, compliance, security, operations, and business stakeholders. They require governance frameworks, not just technical implementations.
But governance is hard. It requires coordination, documentation, and enforcement. It slows down initial delivery if not managed well. So teams skip it, or defer it, or handle it inconsistently across workstreams.
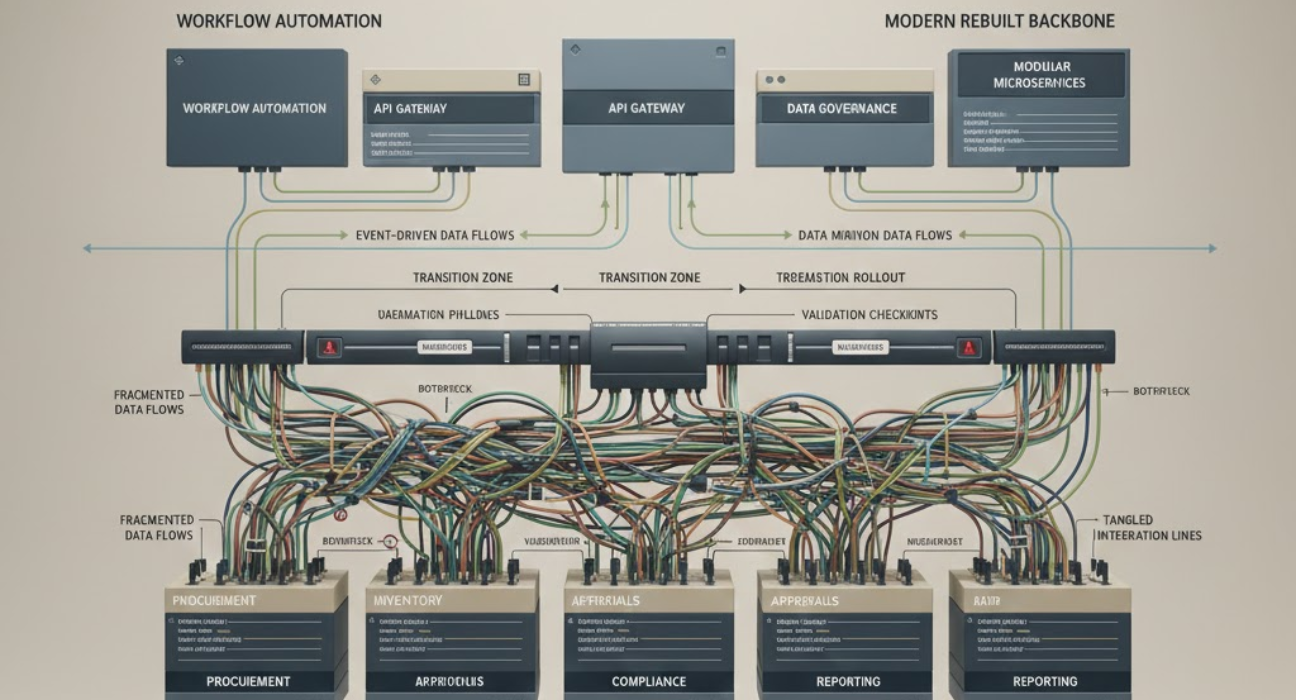
Then the program scales. You have 12 development teams building 30 microservices. Each team logs differently. Each team chooses different monitoring tools. Each team interprets “observability” differently. The result is fragmentation, technically functional, but operationally chaotic.
When production issues arise, engineers spend more time figuring out where to look for information than actually solving problems. Mean time to resolution increases. Finger-pointing begins. Post-mortems identify “lack of visibility” as a root cause, again and again.
This is where mature program management makes the difference. Enterprises that deliver well-established observability standards early, enforce them through architectural review processes, and ensure every team builds with instrumentation as a core requirement, not an afterthought.
What Successful Enterprises Do Differently
Organizations that execute well on enterprise-scale programs approach observability as a strategic capability, not a tactical add-on.
They start by defining clear outcomes. What does good observability enable? Faster incident response. Proactive identification of performance degradation. Compliance with regulatory requirements. Visibility into user experience metrics that inform business decisions. These outcomes shape technical decisions.
They establish standards before development begins. Log formats. Metric naming conventions. Trace propagation requirements. Retention policies. Security controls. These standards aren’t academic exercises they’re enforced through code reviews, automated checks, and architectural governance.
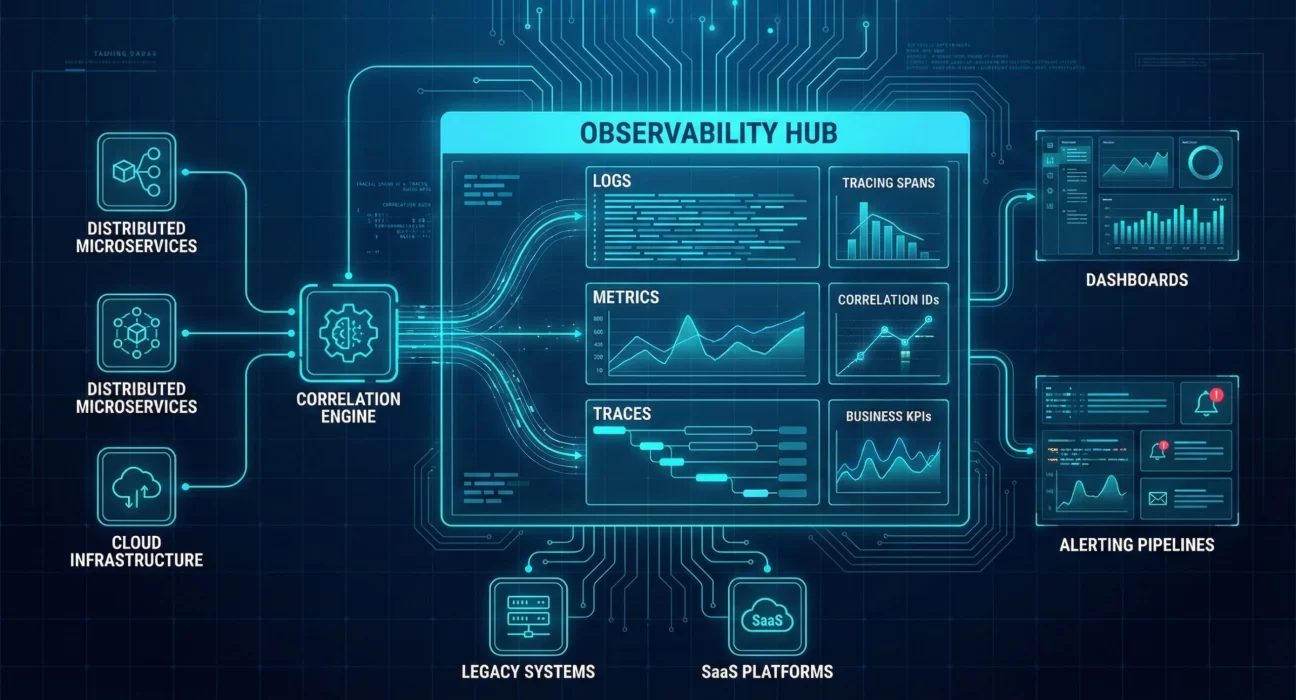
They invest in the right infrastructure early. Centralized logging platforms that can scale. Monitoring solutions that integrate with enterprise authentication and access controls. Distributed tracing systems that work across hybrid cloud environments. Time-series databases optimized for metric storage and query performance.
Most importantly, they treat observability as a shared responsibility. Developers instrument their code properly. Operations teams define SLOs and alert thresholds. Security teams ensure audit requirements are met. Business stakeholders help identify metrics that matter beyond pure technical health.
This doesn’t happen by accident. It requires program leadership that understands observability isn’t just about tools—it’s about organizational alignment, clear ownership, and disciplined execution.
The Role of the Right Partner
Large enterprises often lack the internal expertise to build world-class observability from scratch. Even if they have skilled engineers, those engineers are typically focused on delivering business functionality, not building infrastructure capabilities.
This is where the choice of technology partner matters enormously.
You don’t need a vendor selling you monitoring tools. You need a delivery partner who understands how observability fits into enterprise program execution—someone who has implemented it at scale, across complex environments, with real governance constraints.
Ozrit, for instance, works with enterprises not just to build systems, but to build them in ways that are actually operable, maintainable, and auditable in production. That means thinking about instrumentation during architecture design, not as a post-deployment activity. It means establishing logging and monitoring frameworks that align with enterprise standards and regulatory requirements from day one.
A capable partner brings more than technical skills. They bring execution maturity—an understanding of how to navigate the organizational complexity of enterprise programs, how to get cross-functional alignment on observability requirements, and how to deliver solutions that actually work when you’re running them at scale under real business pressure.
Real-World Constraints That Matter
Theory is easy. Practice is where enterprises struggle.
Consider data sovereignty. If you’re a global enterprise operating in India, your observability infrastructure must respect data residency requirements. Logs containing customer information can’t freely flow to servers in other jurisdictions. This constrains your architectural choices and requires careful design.
Or consider cost. Logging everything might seem prudent until you realize that ingesting, storing, and indexing terabytes of log data daily costs real money. Enterprises need retention strategies that balance compliance requirements, operational needs, and budget realities. This isn’t a technical decision—it’s a business decision that requires CFO-level input.
Then there’s vendor lock-in. Many observability platforms are proprietary and expensive to migrate away from. Choosing the wrong tooling early can trap you in costly licensing models for years. Mature enterprises evaluate not just current capabilities but long-term flexibility, integration options, and total cost of ownership.
Legacy systems add another layer of complexity. Your new microservices architecture might have beautiful observability, but what about the 15-year-old ERP system it integrates with? How do you gain visibility into that interaction? How do you correlate events across modern and legacy platforms? These integration challenges are real, and they require practical engineering, not just best-practice documentation.
Successful execution means navigating these constraints without compromising on the core objectives. It means making pragmatic trade-offs, documenting decisions, and ensuring the observability strategy evolves as the enterprise grows.
From Firefighting to Proactive Operations
The ultimate goal of enterprise-grade observability isn’t just faster troubleshooting; it’s shifting from reactive firefighting to proactive operations.
When you have proper instrumentation, you don’t wait for users to report problems. You detect anomalies before they impact business operations. You identify performance trends that signal capacity constraints before they cause outages. You understand user behavior patterns that inform product decisions.
This shift requires cultural change as much as technical change. Operations teams must move from “keeping the lights on” to continuously improving system reliability. Development teams must accept that instrumentation is part of their delivery responsibility, not something operations bolts on later. Leadership must recognize that investing in observability infrastructure delivers tangible ROI in reduced downtime, faster innovation cycles, and better regulatory compliance.
Enterprises that make this transition successfully tend to share common characteristics. They measure what matters. They automate their monitoring and alerting intelligently. They build dashboards that align with business outcomes, not just technical metrics. They conduct blameless post-mortems that improve systems rather than pointing fingers.
They also invest in people. Observability isn’t just about technology—it’s about having engineers who understand distributed systems, who know how to interpret metrics and logs, who can diagnose complex production issues under pressure. Building that capability takes time, training, and the right organizational culture.
Practical Steps Forward
If you’re leading an enterprise IT transformation or a large-scale software delivery program, here’s what actually matters.
Start by establishing observability as a program-level requirement, not a team-level decision. Define your standards early. Identify your compliance and regulatory constraints. Determine your retention needs and budget thresholds.
Ensure your architecture reviews include observability considerations. Every new service, every integration point, every data pipeline should be designed with instrumentation in mind. This becomes non-negotiable.
Choose your tooling based on your actual requirements, not industry hype. Open-source solutions can work well if you have the expertise to manage them. Commercial platforms offer convenience but come with costs. Evaluate based on your scale, your compliance needs, your team’s capabilities, and your long-term strategy.
Build organizational alignment. Make sure your development, operations, security, and compliance teams all understand their role in the observability strategy. Create forums for cross-functional collaboration. Document decisions and enforce standards.
And partner wisely. If you’re working with external development teams or system integrators, ensure they understand enterprise observability requirements. Verify that they’ve delivered it successfully before in comparable environments. Don’t accept promises, ask for evidence.
The Bottom Line
Logging, monitoring, and observability won’t make headlines in your board presentations. They won’t feature prominently in your digital transformation roadmaps. But they will determine whether your enterprise systems actually deliver on their promises.
When systems fail at scale, stakeholders don’t care about features. They care about recovery time. When auditors ask questions, compliance teams don’t care about architecture diagrams. They care about evidence. When performance degrades, business leaders don’t care about technical debt. They care about customer impact.
Enterprise-grade observability gives you the visibility and control to manage these realities effectively. It’s not glamorous. It’s not optional either.
The enterprises that execute well understand this. They build observability into their programs from the start, govern it properly, and operate it maturely. They choose partners who share that understanding and have proven they can deliver at enterprise scale.
The question isn’t whether you need robust logging, monitoring, and observability. The question is whether you’re building it intentionally or discovering its absence when it’s too late to fix easily.
One approach builds confidence with stakeholders, accelerates delivery, and enables sustainable operations. The other builds technical debt, erodes trust, and creates chronic operational pain.
The choice, ultimately, is about execution discipline. And that’s what separates enterprises that deliver from enterprises that struggle.