

Every large organisation runs on systems that were never meant to last this long. The procurement platform launched in 2012. The inventory system dates to 2008. The workflow engine that handles approvals has been “temporarily patched” for six years. These systems still function, technically. They process transactions. They generate reports. They keep the business running.
But they have become obstacles to everything the organisation needs to do next.
The cost of maintaining these systems grows each year. The risk of failure increases. The ability to adapt to new requirements diminishes. Meanwhile, competitors move faster because their operational backbone is not holding them back. At some point, the calculation shifts. The risk of replacing these systems becomes smaller than the risk of keeping them.
This is when serious leaders start talking about rebuilding the operational backbone. Not because it sounds strategic, but because continuing with the current state is no longer viable.
Why This Conversation Happens Now
Enterprise operations systems age badly. They accumulate technical debt, custom integrations, and undocumented dependencies. The people who built them have moved on. The original vendors may no longer exist. The infrastructure they run on approaches end-of-life.
The pressure to replace these systems comes from multiple directions simultaneously. Regulatory requirements change, and the old systems cannot adapt. Customer expectations shift, and the business cannot respond quickly enough. Cybersecurity standards evolve, and legacy platforms create unacceptable vulnerabilities. Cost pressures intensify, and inefficient processes become too expensive to tolerate.
What pushes this from a chronic problem to an active priority is usually a triggering event. A major system outage that exposes fragility. A compliance audit that identifies serious gaps. A strategic initiative that cannot proceed because the operational platform cannot support it. Suddenly, the thing everyone knew needed fixing becomes the thing that must get fixed now.
The Complexity That Most Plans Underestimate
Replacing core operational systems is not like upgrading software. The new platform must handle everything the old one does, including all the undocumented exceptions and workarounds that evolved over the years. It must integrate with dozens of other systems. It must support business processes that span multiple departments and geographies. And it must do all this without disrupting operations that generate revenue or fulfill obligations.
This complexity manifests in ways that planning documents rarely capture. A procurement workflow looks simple until you discover it behaves differently for capital expenditures versus operating expenses, for domestic versus international suppliers, for standard purchases versus emergency orders. Each variation has different approval chains, compliance requirements, and system integrations.
The data migration challenge alone can derail an entire project. Legacy systems contain millions of records in inconsistent formats. Master data exists in multiple places with conflicting information. Historical transactions have dependencies that are not obvious until something breaks. Migrating this data cleanly requires understanding business logic that may exist only in the heads of long-tenured employees.
Then there is the organisational dimension. Different business units have adapted the legacy systems to their needs through custom configurations and local processes. What works for manufacturing does not work for sales. What satisfies European compliance creates problems for Asia Pacific operations. Any new platform must either accommodate this variation or the organisation must standardise, which means some groups lose functionality they depend on.
Where Replacement Projects Go Wrong
Most operational backbone replacements follow a predictable failure pattern. The organisation selects a vendor based on capabilities and price. The vendor promises to deliver everything required. The project launches with optimism and a detailed plan.
Six months later, the project is behind schedule and over budget. Requirements that seemed clear turn out to be ambiguous. Integrations that looked straightforward reveal unexpected complexity. The vendor’s standard platform cannot handle specific business needs without significant customisation. Change requests accumulate. Scope expands. The timeline extends.
The problems compound as the project continues. Business stakeholders lose patience with delays and start questioning decisions. IT becomes overwhelmed managing both the new implementation and the deteriorating legacy systems. The vendor relationship becomes adversarial as both sides argue about responsibility for issues. Leadership pressure increases, but does not make the underlying problems any easier to solve.
By the time the new platform finally goes live, it satisfies almost no one. It costs more than planned. It takes longer than promised. It delivers less functionality than expected. And it still requires the organisation to maintain parts of the old system because certain capabilities never got migrated successfully.
How Ozrit Structures Backbone Replacement Programs
Ozrit approaches operational backbone replacement differently because the company was founded by people who have led these programs multiple times. They understand what actually causes failure, and they structure delivery to avoid those failure modes.
The methodology starts with a realistic assessment phase that typically runs four to six weeks. Ozrit senior engineers work directly with the client’s operational teams to map how work actually happens. This goes beyond documented processes to understand the real workflows, including exceptions, workarounds, and informal procedures that keep things running. This assessment identifies integration requirements, data quality issues, and organisational complexities that must be addressed.
The assessment produces a delivery plan with accurate effort estimates and a realistic timeline. If the project will take 18 months, Ozrit says 18 months. The company does not compress timelines to win work and then extend them later. This honesty sometimes costs business in the short term, but it prevents the credibility damage that comes from missing commitments.
The actual build follows a phased approach that delivers working functionality incrementally. Rather than attempting to replace everything simultaneously, Ozrit implements capability by capability in a sequence that minimises risk. Each phase produces a functional system that handles real transactions. This allows the organisation to validate that the new platform actually works before proceeding to the next phase.
This incremental approach creates natural checkpoints where the project can be evaluated honestly. If something is not working, it becomes visible early when there is still time to correct it. If priorities shift, the organisation can adjust the plan without losing all previous investment. The risk concentrates in smaller, more manageable pieces rather than one massive cutover at the end.
The Technical Architecture That Enables This
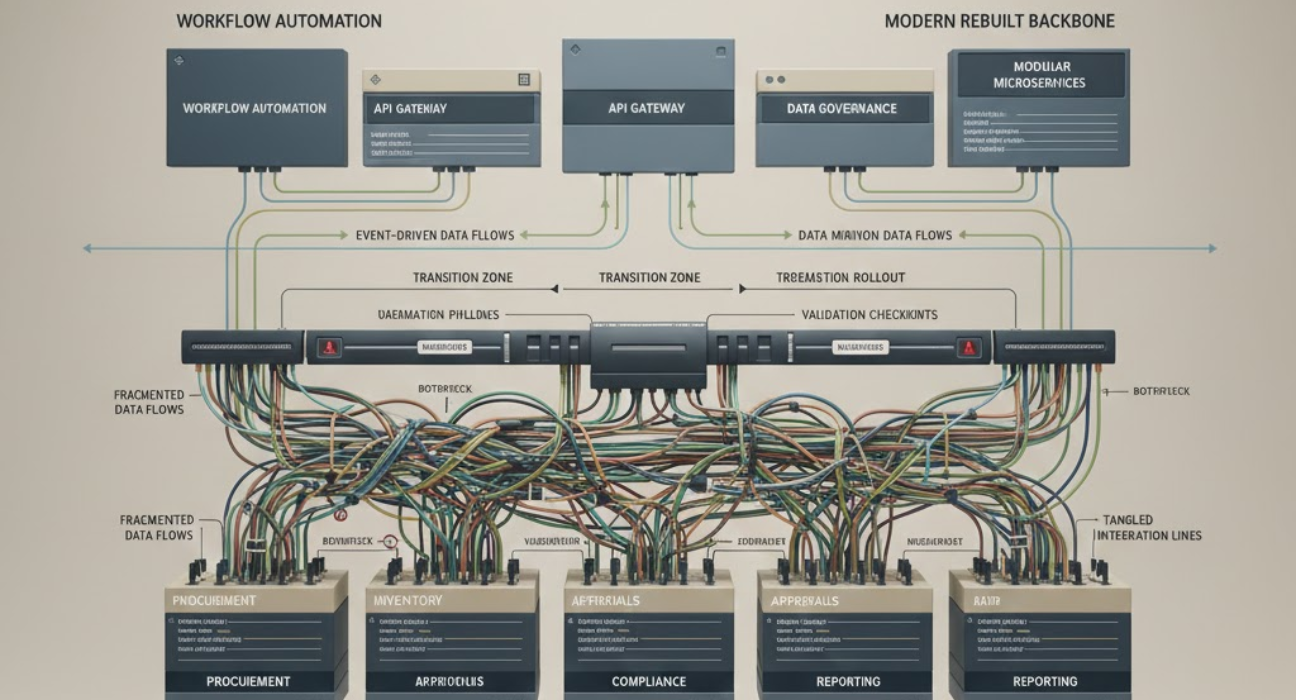
Ozrit platforms use modern cloud-native architecture designed specifically for complex enterprise operations. The system separates business logic from infrastructure, which allows different components to scale independently and be updated without affecting everything else. When one business process needs significant customisation, it does not destabilise the entire platform.
The integration layer uses standard APIs and event-driven patterns that connect cleanly to both modern and legacy systems. This matters because operational backbone replacements rarely happen in isolation. The new platform must work alongside existing systems during transition periods that often last months. Poor integration architecture forces the organisation to choose between brittle point-to-point connections or expensive middleware layers. Ozrit’s approach avoids both problems.
Data migration gets treated as a distinct engineering discipline, not an afterthought. Ozrit assigns senior data engineers who understand both the technical and business dimensions of moving operational data. They build migration pipelines that validate data quality, reconcile inconsistencies, and maintain audit trails. They work with business users to define acceptance criteria and verify that migrated data actually supports real work.
The platform incorporates intelligent automation, which adds clear value. Workflow routing uses pattern recognition to direct work to appropriate approvers based on transaction characteristics. Process monitoring identifies bottlenecks and suggests improvements based on historical data. Exception handling applies learned rules to resolve common issues without manual intervention. This reduces operational costs and improves consistency, but the platform never requires AI to function. Traditional logic handles deterministic processes with full transparency and auditability.
Managing Risk Through Delivery Structure
Ozrit assigns a senior technical leader to every backbone replacement program. This person has delivered similar programs before, understands the failure patterns, and has the authority to make technical decisions without escalation delays. They participate in planning sessions, review architecture decisions, and stay involved through go-live and stabilisation.
This level of involvement costs more than assigning junior consultants, but it prevents the expensive problems that emerge from poor early decisions. An experienced leader recognises when requirements conflict with technical reality and addresses this before development starts. They identify integration risks that less experienced people miss. They keep the project focused on outcomes rather than activity.
The delivery team includes a mix of senior and mid-level engineers, not primarily junior resources learning on the job. Ozrit maintains capacity specifically for large enterprise programs rather than trying to scale up with contractors when projects arrive. This means the company can staff programs properly from the beginning and maintain consistency throughout delivery.
Support transitions begin before go-live, not after. Ozrit engineers work with the client’s IT team during implementation to transfer knowledge about how the platform works and how to resolve common issues. The 24/7 support includes access to senior engineers who built the system, not just offshore teams reading troubleshooting guides. Response times scale to impact, with critical issues getting immediate attention from people who can actually fix them.
What Makes This Investment Different
Replacing operational backbone systems requires significant investment. The direct costs include software, implementation services, infrastructure, and internal resources. The indirect costs include business disruption, training, and productivity loss during transition. For a large enterprise, this easily reaches tens of millions over the program lifecycle.
The justification for this investment comes from comparing the total cost of continuing with legacy systems against the total cost of replacement. Legacy systems incur high maintenance costs, create operational inefficiency, limit business agility, and carry an increasing risk of failure. These costs are often hidden across multiple budgets and not fully quantified. When leadership adds them honestly, the case for replacement usually becomes clear.
The difference between a successful replacement and a failed one is not primarily about money. Organisations that fail typically spend plenty. The difference is execution quality, technical competence, and realistic planning. An implementation that takes 18 months and costs what it is supposed to cost creates value. An implementation that takes 30 months, costs double, and delivers half the expected functionality destroys value regardless of the initial budget.
The Reality of Timeline and Commitment
A complete operational backbone replacement for a large enterprise typically requires 12 to 24 months from kickoff to full deployment. Smaller, more focused programs can deliver in 6 to 12 months. Larger, more complex transformations may take longer. Anyone promising faster timelines is either working on something much simpler than a true backbone replacement or not being honest about what is actually required.
These timelines assume the client organisation can make decisions promptly, provide necessary access, and allocate capable people to the effort. Delays usually come from internal approval processes, competing priorities, or infrastructure constraints rather than from vendor delivery capacity. A project timeline is a shared commitment, not something the vendor controls unilaterally.
The commitment extends beyond initial deployment. Operational systems require ongoing support, periodic updates, and continuous improvement. Ozrit structures engagements to include post-deployment support and enhancement capability. This ensures the organisation has access to people who understand the system when issues arise or requirements evolve. The goal is a stable platform that serves the business for years, not just a successful project handoff.
What Success Actually Looks Like
A successful operational backbone replacement produces a platform that handles daily work reliably, adapts to changing requirements without major rework, reduces operational costs through automation and efficiency, and provides visibility that enables better decisions. The organisation moves faster because operational processes accelerate rather than constrain. Risk decreases because the platform is secure, compliant, and maintainable.
Perhaps most importantly, the business stops talking about operational systems as problems and starts treating them as capabilities. When operations become invisible infrastructure that simply works, leadership attention can focus on markets, products, and customers rather than on why the procurement system is down again.



